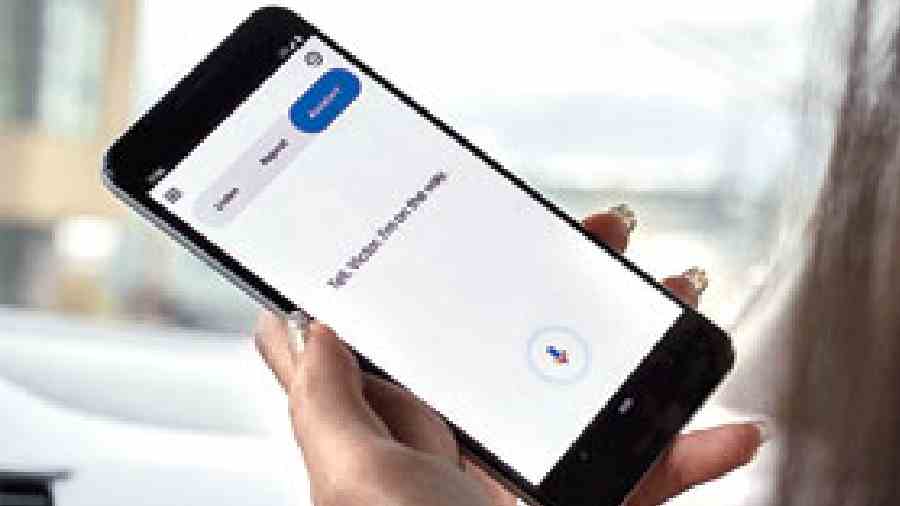
Google is constantly working on ways to make speech-and-language-related projects as inclusive as possible. Project Relate is an app for Android, which helps individuals with non-standard speech communicate more easily in face-to-face conversations.
The company has been piloting the app with English users in India, and will be expanding this pilot to Hindi users in early 2023. Through this project, Google’s endeavour is to make products that rely on speech recognition technology, like Google Assistant, more accessible to everyone.
There are three core features to the app — Listen, Repeat and Assistant. Listen transcribes speeches in real-time, allowing users to copy and paste it into other apps besides allowing people to read what is being said. Repeat will repeat what is said into a clear voice and Assistant lets users speak directly to the Google Assistant for smart assistant jobs.
Users record 500 phrases to train the app to understand their speech, and then receive a personalised model to interact with the app’s three features.
Google is also focusing on Indian languages more than before. The company has announced a collaboration with the Indian Institute of Science, Bangalore for Project Vaani, which help capture diverse Indian dialects for building better AI language models. This collaboration will collect and transcribe open-source speech data from across all of India’s 773 districts, making it available through the Central government’s Bhashini project in the future.
“The corpus of natural language data in digital forms, even in idealised forms of languages like Hindi and Marathi, is magnitudes smaller than that available in English or other Western languages. It is miniscule or almost non-existent in comparison if you take some variants spoken even by millions. As a result, automatic speech recognition (ASR) models trained on Hindi fails for Bhojpuri speakers of Bihar and eastern UP. When Bengali alone is said to have 50 variants, one can hardly expect data biased towards urban, young, male speakers to be good enough for training language models that understand rural, middle-aged, female speakers,” reads a statement from Indian Institute of Science, Bangalore.








